C++注解
程序的编译链接原理
我们需要理解分析编译的过程理解打好坚实的C++基础,需要理解.o文件的格式组成,可执行文件的组成格式又是什么样子,理解符号表的输出符号,符号何时分配虚拟地址。这些能够帮助我们在出现问题时, 能够深入理解并快速找到问题
以下结合示例演示大概原理
工程结构为
1
2
3
4
5
| .
├── sum01.cpp
└── test01.cpp
0 directories, 2 files
|
sum01:
1
2
3
4
| int gdata = 10;
int sum(int a, int b){
return a + b;
}
|
test01:
1
2
3
4
5
6
7
8
9
| extern int gdata;
int sum(int, int);
int data = 20;
int main() {
int a = gdata;
int b = data;
int ret = sum(a, b);
return 0;
}
|
编译
进行编译过程大局分为三个阶段
所有的源文件都是单独编译的
- 预编译
- 编译
- 汇编
这三个步骤最终得到
二进制的可重定位的目标文件
预编译
处理 #开头的命令 ,常见的define ,include 等
需要注意的是
#pragma lib #pragma link 等等,这几个并不是在预编译的时间处理,而是在链接阶段
编译
语法分析
语义分析
代码优化
这就是编译器的基础必须的工作了
而代码优化 是一个可选的操作,我们可以在编译命令中添加指定 优化参数,比如 O1 O2 O3
这里我们执行生成.o文件指令
1
2
| gcc -o *.cpp -g
#加入-g 是为了可调式状态下方便看到对应的代码
|
得到两个文件我们可以观察两个文件的符号表(输入指令)
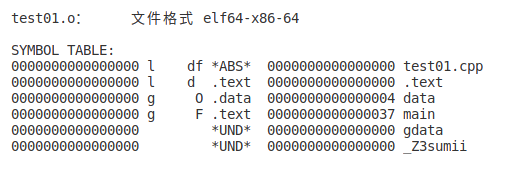
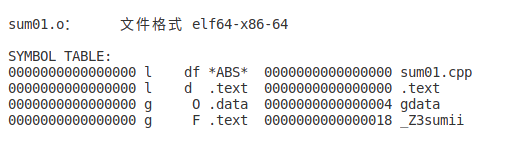
可以看到各个符号所分配的段注:l 为local g 为global
我们观察两个文件的代码段生成的对应的汇编语言指令
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| Disassembly of section .text:
0000000000000000 <main>:
extern int gdata;
int sum(int, int);
int data = 20;
int main() {
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 48 83 ec 10 sub $0x10,%rsp
int a = gdata;
c: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # 12 <main+0x12>
12: 89 45 f4 mov %eax,-0xc(%rbp)
int b = data;
15: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # 1b <main+0x1b>
1b: 89 45 f8 mov %eax,-0x8(%rbp)
int ret = sum(a, b);
1e: 8b 55 f8 mov -0x8(%rbp),%edx
21: 8b 45 f4 mov -0xc(%rbp),%eax
24: 89 d6 mov %edx,%esi
26: 89 c7 mov %eax,%edi
28: e8 00 00 00 00 call 2d <main+0x2d>
2d: 89 45 fc mov %eax,-0x4(%rbp)
return 0;
30: b8 00 00 00 00 mov $0x0,%eax
35: c9 leave
36: c3 ret
########################################################
0000000000000000 <_Z3sumii>:
int gdata = 10;
int sum(int a, int b) {
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 89 7d fc mov %edi,-0x4(%rbp)
b: 89 75 f8 mov %esi,-0x8(%rbp)
return a + b;
e: 8b 55 fc mov -0x4(%rbp),%edx
11: 8b 45 f8 mov -0x8(%rbp),%eax
14: 01 d0 add %edx,%eax
16: 5d pop %rbp
17: c3 ret
|
不难发现,所有的符号都没有分配虚拟地址,而链接的工作就是将两个独立的文件进行整合,从而分配虚拟地址
汇编
生成相应平台的汇编指令
最终生成可重定位的目标文件
符号表(section table)与各种段(.text, .data .bss等) elf头
更详细的部分就需要深入 书籍csapp,《程序员的自我修养》
链接
而编译之后就要进行链接
链接的大体概念就是将单独编译的目标文件们与各类库文件(比如静态库文件)整合为可执行程序
而链接也分为两个核心的步骤
- 合并解析
- 符号重定位
最终得到可执行的文件
我们输入链接指令
可以得到一个可执行文件 a. out
合并解析
所有.o文件的各种段的合并
符号表合并后,进行符号解析。
相应段进行合并 .text <=> .text
符号解析
所有对符号的引用都要找到该符号定义的地方
实际上敲代码编译不通过 常犯的就是符号未定义和符号重定义的问题
需要注意的是:此时的符号是没有分配任何地址的,特指这个链接的符号解析阶段
观察a.out的汇编代码和编译的.o文件的汇编代码进行对比我们可以发现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| a.out: 文件格式 elf64-x86-64
Disassembly of section .text:
0000000000401000 <_Z3sumii>:
int gdata = 10;
int sum(int a, int b) {
401000: f3 0f 1e fa endbr64
401004: 55 push %rbp
401005: 48 89 e5 mov %rsp,%rbp
401008: 89 7d fc mov %edi,-0x4(%rbp)
40100b: 89 75 f8 mov %esi,-0x8(%rbp)
return a + b;
40100e: 8b 55 fc mov -0x4(%rbp),%edx
401011: 8b 45 f8 mov -0x8(%rbp),%eax
401014: 01 d0 add %edx,%eax
401016: 5d pop %rbp
401017: c3 ret
0000000000401018 <main>:
extern int gdata;
int sum(int, int);
int data = 20;
int main() {
401018: f3 0f 1e fa endbr64
40101c: 55 push %rbp
40101d: 48 89 e5 mov %rsp,%rbp
401020: 48 83 ec 10 sub $0x10,%rsp
int a = gdata;
401024: 8b 05 d6 2f 00 00 mov 0x2fd6(%rip),%eax # 404000 <gdata>
40102a: 89 45 f4 mov %eax,-0xc(%rbp)
int b = data;
40102d: 8b 05 d1 2f 00 00 mov 0x2fd1(%rip),%eax # 404004 <data>
401033: 89 45 f8 mov %eax,-0x8(%rbp)
int ret = sum(a, b);
401036: 8b 55 f8 mov -0x8(%rbp),%edx
401039: 8b 45 f4 mov -0xc(%rbp),%eax
40103c: 89 d6 mov %edx,%esi
40103e: 89 c7 mov %eax,%edi
401040: e8 bb ff ff ff call 401000 <_Z3sumii>
401045: 89 45 fc mov %eax,-0x4(%rbp)
return 0;
401048: b8 00 00 00 00 mov $0x0,%eax
40104d: c9 leave
40104e: c3 ret
|
符号重定位
符号的重定位(重定向)
对比两份.o文件的符号表,发现生成的.out 文件中两个引用全局符号放到了各自应该所在的段,不再是*UND*
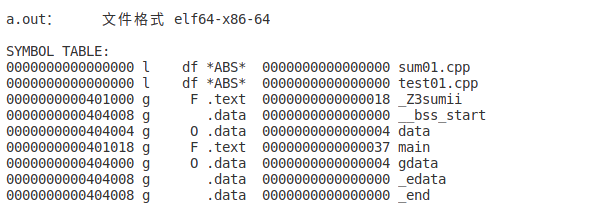
并且给所有的符号分配虚拟地址
观察elf头
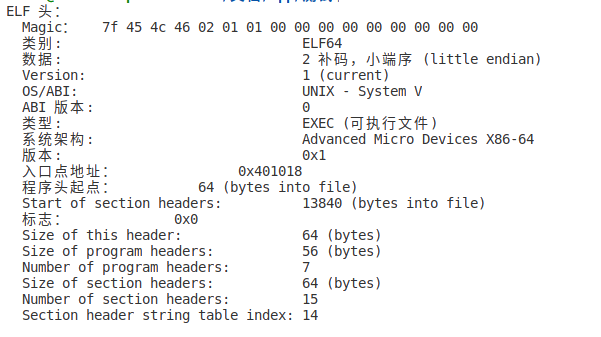
从elf头,可以发现文件类型变为了可执行文件 入口点地址 就是 main函数指令地址
观察可以发现
最终的可执行文件 可以发现与.o 文件的内里格式几乎一致,但是不同的是多了一个
program headers (程序头)

而这个程序头的作用告诉系统需要把那些内容加载到内存当中,
可以发现最先执行映射的就是.text 与.data段(其他段是GDB 特有的调试段节
所以最终执行程序的时候
就是将a.out 中的个个段映射到系统给进程分配的空间上执行